Haiku Update; Spring 5, Better Inter-op and Docker Build
In recent months I have continued to implement some improvements in the Haiku system.
HaikuDepotServer Using Spring 5
HaikuDepotServer was started in 2013 and at this time it was still common to use XML to define the Spring environment. In the intervening years it has become more common to use Java classes in order to perform the same configuration tasks. This is helpful because the java logic is more flexible, breaks on some problems at compile-time and one can also breakpoint code whereas the same thing cannot be achieved with XML files.
To achieve this migration, one uses special Spring-specific annotations such as @Configuration and @PropertySource amongst others. I’ve resisted making the change until now because the work yields no tangible value, but in the last month I decided to make this change and move to Spring 5 (from 4) at the same time.
The change was surprisingly not too hard to achieve and because I was forced to work through the configuration manually, it presented a good opportunity to clean-up and rationalize much of the configuration. At the same time I also took the opportunity to implement constructor-based injection as well as moving the web.xml mostly over to Java classes as well — thanks to the Servlet 3 standard this is now possible.
HaikuDepot and Fetching Data
When the desktop application runs it needs to get some bulk data from the HaikuDepotServer (HDS) system. The biggest thing it needs is the meta-data for the packages in each repository, but also icons as well as meta-data about the packages themselves. This is illustrated in the diagram below.
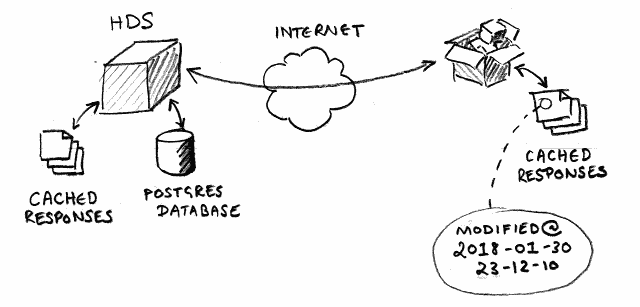
The server has a database of data containing the information about the packages. The client calls the server including the “last modified” date of the data and the server responds with new data if it has anything newer. The server caches the data so that it can re-use it and the client also caches the response.
Client Side Parsing JSON
My C++ platform mini-project from early 2017 on bulk JSON-processing worked out. I changed HaikuDepotServer (HDS) to generate it’s bulk-data DTO objects from json-schema as part of the build system and then created Python scripts to generate C++ DTOs as well as accompanying Haiku-specific JSON parsers for those models. It took a while to write the scripts, but now any further parsing should be easier, result in tidier C++ client code and the whole mechanic ought to be cleaner. The biggest win with this change though is providing a better mechanic for HaikuDepot clients to coordinate cached data from the HDS system.
The actual data itself is not so huge at the moment. The largest repository is approximately 2.5MB, but is growing and this download mechanic should scale with it.
Server Side Preparing Data
On the server-side, the HDS “Job Service” is tasked with generating these payloads for download. It will generate the response payload once and then re-use the same payload off disk-cache to service other requests. Care has been taken in the case of downloading packages for a repository that very few SQL queries are required and that the assembly process is efficient. Likewise maintaining data-freshness dates in-memory helps reduce the cost of handling If-Modified-Since HTTP headers and caching.
Some improvements server-side are still possible. It would be advantageous for example if the response streamed-out as it was generated. It would be good if the system pro-actively generated updates to the downloaded data in the background. These and other improvement are hopefully a logical extension of what is already in place and working now.
Client Side Threading and State Machine for Bulk Download
Another change made in the C++ was breaking the download logic into distinct parts and also breaking this logic away from the Model class that was simply becoming too large to work with. As part of this, I decided to create a download-bulk-data state machine and to run the bulk downloads concurrently.

The task sequencing is shown in the diagram above. Essentially some meta-data and information about repositories needs to be downloaded first and then all of the repositories’ package-data needs to be downloaded and that can happen concurrently. Data is split between repositories like this to avoid extraneous data being stored client-side without purpose and also to reduce the overall transmitted data.
The state machine handles failure, success and orchestrates the process. Hopefully the state machine will be more easily adapted to use with non-blocking IO if that is possible in the Haiku HTTP client in the future.
As part of this work, I have improved the logging and also handling for situations where network connections are not present.
Haiku Build with Docker
Recently the X-Code dev tools on my mac were updated and this broke the Haiku cross-compile build. To work around this until clang is functional for me again, I have figured out how to create a debian-based build environment in Docker that builds off source resident on the host machine. You can find this here with instructions.