Revisiting Haiku Depot and Performance Around Bulk Data
Note that HDS is a long-running, open-source and non-funded project and so this analysis weighs up the cost:benefit of any intervention together with the probability that enough effort can be expended to undertake any improvement.
Background
Haiku Depot Server (HDS) (source) is an application server vending curated package-related data for the Haiku operating system. The HDS project was started in 2013.
There are a handful of bulk data payloads supplied from HDS. These cases are;
- Repositories (localized) as
.json.gz - Package data for a single repository (localized) as
.json.gz - Icon data for all packages as
.tgz
This data is typically consumed by the desktop application Haiku Depot (HD). HD will typically maintain a cache of this data locally.
The workflow for accessing data in these cases is as follows;
- HD requests the data from a well-known endpoint vended by HDS. If HD already has some cached data, it includes an
If-Modified-Sinceheader to the request so that the HDS server knows how fresh the HD client’s data is. - If HDS sees that the
If-Modified-Sinceheader is the same age as the data in the database then it signals this back to the client. The client can then assume the client-side cache is still valid so there is no need to request fresh data. Stop. - If HDS observes that it has no cached data on the server-side from a prior request or the data in the database is newer than that cached then it starts a job to regenerate the data. HDS waits for the job to complete. If on the other hand, the existing cached data from a prior job is not stale then it simply uses that.
- The HDS system sends a redirect back to the HD client instructing it to redirect its request back to pick-up the job data.
- The HD client makes a new request back to HDS to pickup the request data.
- HDS delivers the data payload back to the client.
- The HD client caches the data.
- The HD client consumes the data.
The value for the If-Modified-Since HTTP header is derived from information encoded into the HD cached data payload itself. This can be seen by reviewing the HD cached data typically found at ~/config/cache/HaikuDepot;
cat pkg-all-haikuports_x86_64-de.json.gz | gzip -d | jq | less
Example data is;
{
"info": {
"createTimestamp": 1670407593030,
"createTimestampIso": "2022-12-07 10:06:33",
"dataModifiedTimestamp": 1670406745000,
"dataModifiedTimestampIso": "2022-12-07 09:52:25",
"agent": "hds",
"agentVersion": "1.0.134"
},
"items": [
{
"name": "burnitnow",
"createTimestamp": 1428741186489,
"modifyTimestamp": 1609696360189,
"prominenceOrdering": 100,
...
In the case of the bulk icon data, the compressed tar-ball contains a JSON file that carries analogous data.
This architecture replaced a previous RPC mechanism used earlier in the evolution of the HD and HDS applications. The current process is simple to understand, has worked well over a 5-7 year period and has a simple deployment mechanism requiring little or no intervention.
If HD requires data from HDS and HDS has no data cached then HDS must generate the data immediately leaving the HD client waiting. This generated data is assembled from the relational database using optimised SQL queries. Over time, the HDS database has grown in size leading to longer delays generating the data and hence longer delays for the HD client. This is slowly becoming problematic and represents a current (non serious or urgent) issue, but is essentially what this article is trying to address.
Additional Considerations
There are also some other points where possible future scaling limits could be met around bulk data, although it is unclear if or when this might happen;
- HDS is currently deployed as a single instance. This does not present a current concrete problem but redundancy would be ideal, and it is possible that in the future a single instance may be overwhelmed.
- Traffic will be hitting the core HDS application located in a single geography and is then subsequently retrieving the bulk data from that same geography regardless of the location of the HD client. This means the users may be experiencing delays owing to the extended transmission time over wider geographic distances than might be necessary if a CDN service were employed.
- The HDS application currently scales screenshots for client needs in real time. The time required to scale the image causes a delay for HD as the client has to wait for the scaling to occur.
These additional considerations do not need addressing short-term, but can play into the solution.
Ideal Solution
Assuming continued growth of the database, at some point in the future, the dynamic generation of the bulk data is going to become too noticably slow to service the HD client in quasi real time. Instead, pre-prepared bulk data payloads should be cached for HD clients to download. The cached data would persist and be retained across application-server restarts and be managed by redundant HDS servers. This approach brings additional inherent complexities into play both in terms of the software as well as the deployment.
The files will need to be stored in a separate file store. As changes are made in the HDS database, these changes need to be reflected in the persisted files for HD clients to download.
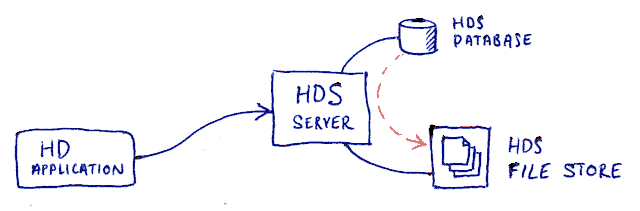
By always having the data available as a file that gets updated, the HD client will never have to wait for the assembly of the bulk data; resolving the core problem that needs to be addressed.
Some files are localized so there will need to be variants generated for each natural language such as Mandarin, German, French or Spanish.
pkg-all-haikuports_x86_64-zh.json.gzpkg-all-haikuports_x86_64-de.json.gzpkg-all-haikuports_x86_64-fr.json.gzpkg-all-haikuports_x86_64-es.json.gz
Even if there are no HD clients requesting bulk data for a particular language, HDS would still need to generate the bulk data files for it just in case a user comes along requiring that language. On the other hand, some languages are not yet localized for in HDS’s dataset; an example being the Māori language at the time of writing. HDS would need to maintain a list of languages for which it could produce bulk data files. If an HD client requests bulk data for another “unsupported” language then the HD client would be delivered the English language data as a reasonable fallback.
It would be impractical or inefficient to regenerate all of these bulk data files each time that any data related to a repository changed. It would be better if the regeneration of the files occurred X minutes after a change to a repository’s data is settled and no further changes are made for that repository. This delay means that data consumed by HD clients may be slightly stale, but it is better than excessive re-generation of the data causing excessive load on the HDS system.
To achieve this, a queue is introduced such as Rabbit-MQ. HDS will enqueue an command message indicating that the data of a repository has changed. The message will have delayed delivery and the queue will have coalesced behaviour. Even if HDS is restarted or there are multiple HDS instances deployed, the message will still eventually be consumed.
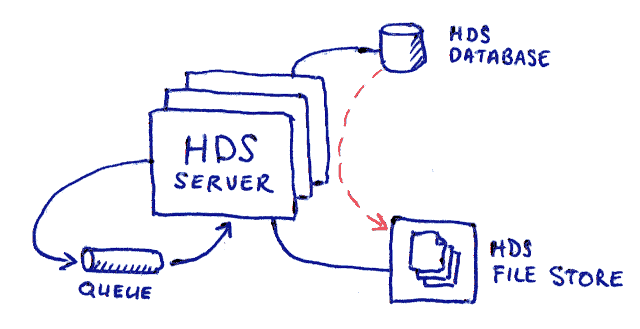
Command messages will be required such as;
- Regenerate repository bulk data
- Regenerate icon bulk data
An application lock mechanism will need to be employed so that across the HDS instances only one HDS application server is able to generate the files at a time. The easiest way to achieve this is to use a Postgres Advisory Lock because Postgres is already used by HDS for the storage of the system’s data.
HDS will need to monitor the last modified timestamp in the data files. Note this is not the timestamp of the bulk data file in storage, but instead the timestamp of the data itself as is outlined above. HDS needs to be aware of this because it will still need to handle the If-Modified-Since HTTP header from the HD client.
To achieve this, HDS will maintain a database table containing the bulk data file in the file storage and the modified timestamp. This may lead to the possibility of a data anomaly occuring between the database and the reality in the stored files.
If the situation arises where, through some error or corruption, a file is not available for an HD client then it should return a 409 Conflict HTTP response. The client will register this as an error and will then signal it to the human user.
A function is required wherein all of the data can be regenerated. Possibly it may make sense to run this during daily maintenance as a self-healing mechanism.
Additional Considerations
HDS is currently deployed as a single instance
Currently the HDS system relies on caching in the application server to reduce load on the database server. To provide eventual consistency in the caches, a messaging system is required between the HDS instances. The message broker, Rabbit-MQ, described in this solution would also facilitate that, but in reality it is probably better to drop the complexity of distributed query caches for mutable data and instead simply drive more workload into the database.
Also the job execution system for tasks such as repository import are in-process only and would need to be queued. Most likely since this project began, off-the-shelf task queue systems have emerged such as Spring Batch which would be able to replace the bespoke system in HDS.
Some tasks cannot occur concurrently such as repository ingestion. In such cases, application-locks may be required to avoid concurrency issues.
Traffic will be hitting the core HDS application located in a single geography…
The new bulk data architecture presented here could also store and distribute data via a CDN or CDN-like system if this were eventually required.
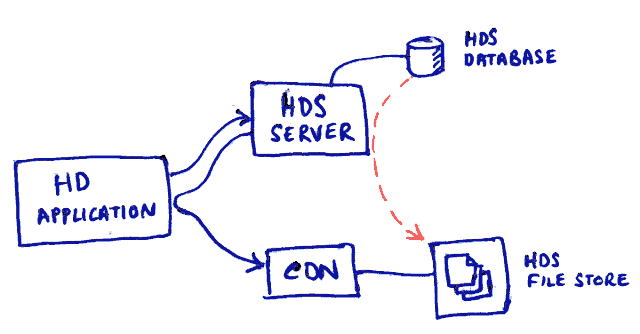
The HDS application currently scales screenshots for client needs in real time
As part of the implementation of this solution, the storage abstractions should also consider the eventual needs of the screenshot storage. It will eventually make sense to move the screenshots out of the core database and into some file storage that is backed up. In this case a set of “standard sizes” will be required rather than allowing the client to specify what size it wants to request.
Summary
This change most likely makes sense, but in the end will call for more complex software and deployment. The change will also require a considerable effort to achieve. A short-term approach can be taken to avoid too much work and change happening at once.
In order to avoid the overhead of the messaging broker, it is probably easiest to continue to assume a single-instance deployment and run a delay queue in-memory for the generation of the bulk data. In this case, the largest short-term deployment change would be the attached storage. Short-term owing to the single-instance, a volume mount could be used. The volume would need to be backed up in close coordination with the main database.
Application structures and processes should anticipate the wider changes in the future noted above.
This will most likely resolve the short-term issue.